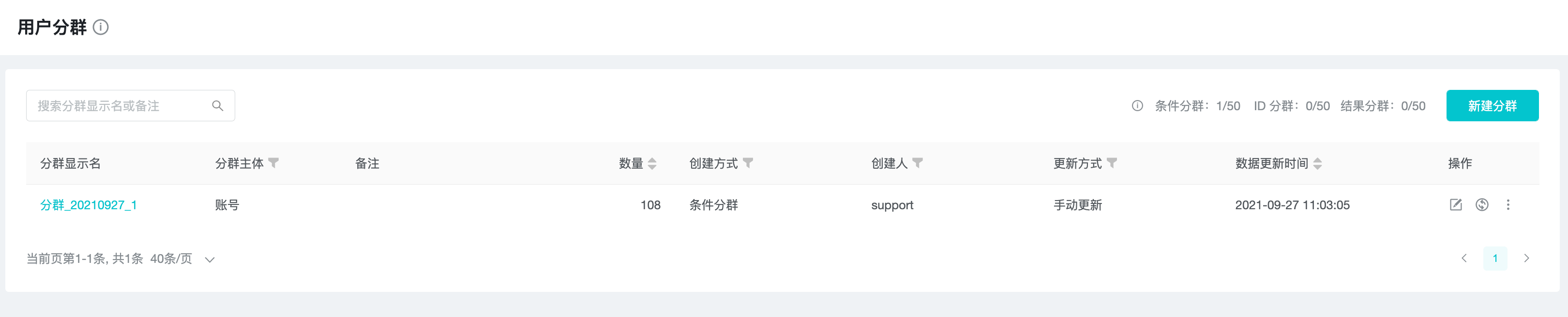
用户分群
1. 概述
将符合一定属性和行为特征的用户划分为一个群体,并对该群体进行研究和分析的方式,即用户分群。
TapDB 的分析模型中分别以「账号」、「设备」作为查询主体进行查询,在用户分群中同样支持分别以「账号」、「设备」作为主体进行分群。
目前提供「条件分群」、「ID 分群」、「结果分群」3 种分群方式。
2. 适用角色与用途
| 角色 | 用途 |
|---|---|
| 分析师 / 业务人员 | 划分特定用户群体,用以聚焦分析、排除干扰或导出用户列表等 |
3. 创建用户分群
3.1 条件分群
点击分群列表右上角的新建分群,选择「新建条件分群」;此处请注意分群使用进度。
新建条件分群页分为「基础信息」、「分群规则」两部分。
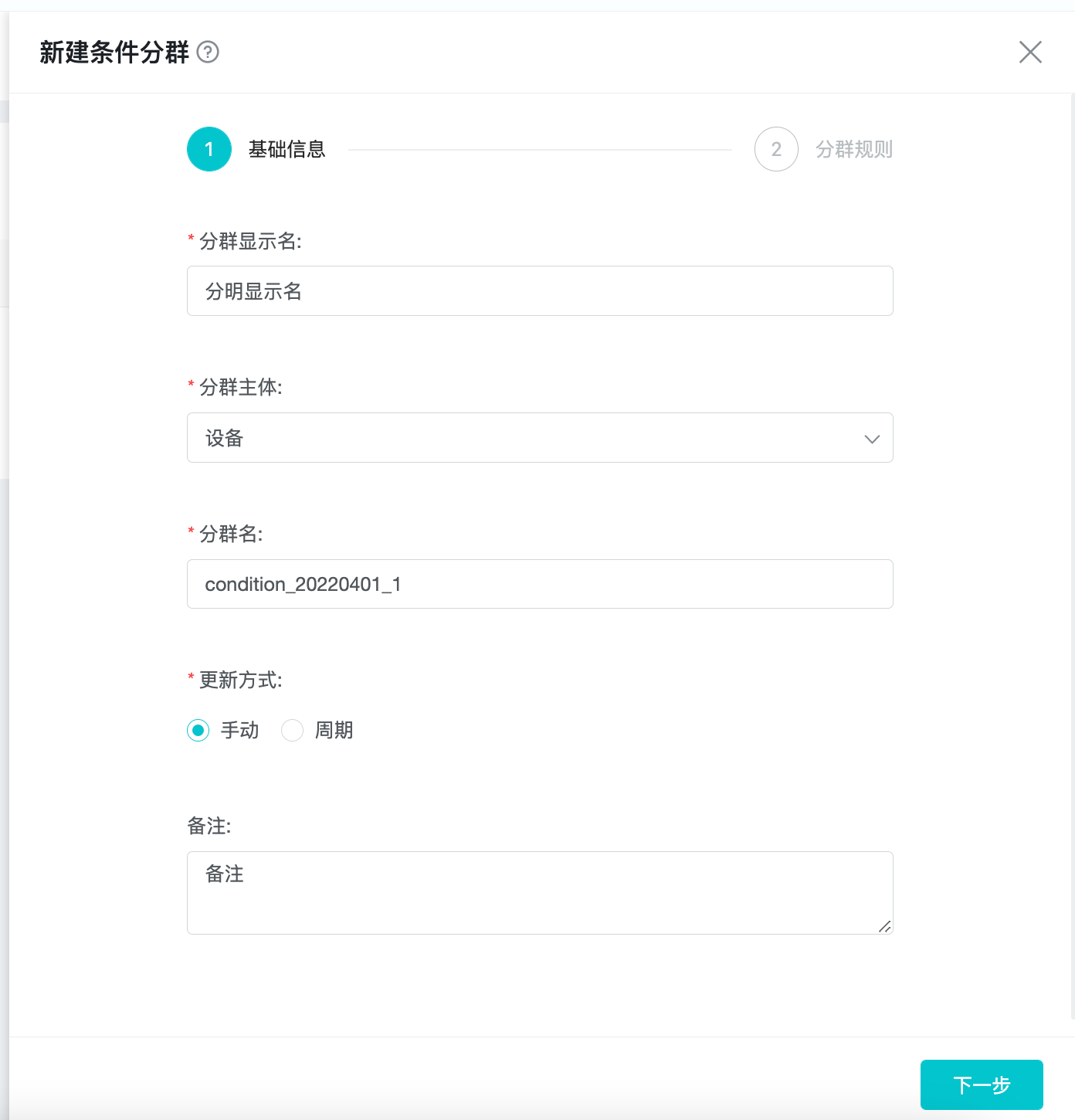
在「基础信息」页,依次录入或选择「分群名、分群主体、分群代码、更新方式、备注」。
分群名展示在分群列表、分析模型中,是业务人员识别分群的依据。
分群主体,支持「账号 ID」或「设备 ID」,根据业务场景做选择。
分群代码是分群存储在系统后台的唯一标识,为方便数据分析人员直接查询数据库表,可命名为带有业务含义的参数名。
更新方式分为「手动更新」与「自动更新」。「手动更新」指在完成首次计算后,系统不会自动更新用户群,用户需要手动�进行更新;「自动更新」会在每日 0 点后,以前一日作为基准进行用户群更新,可以设置更新延迟以确保所有前一日的数据都接收到,保证数据完整性。
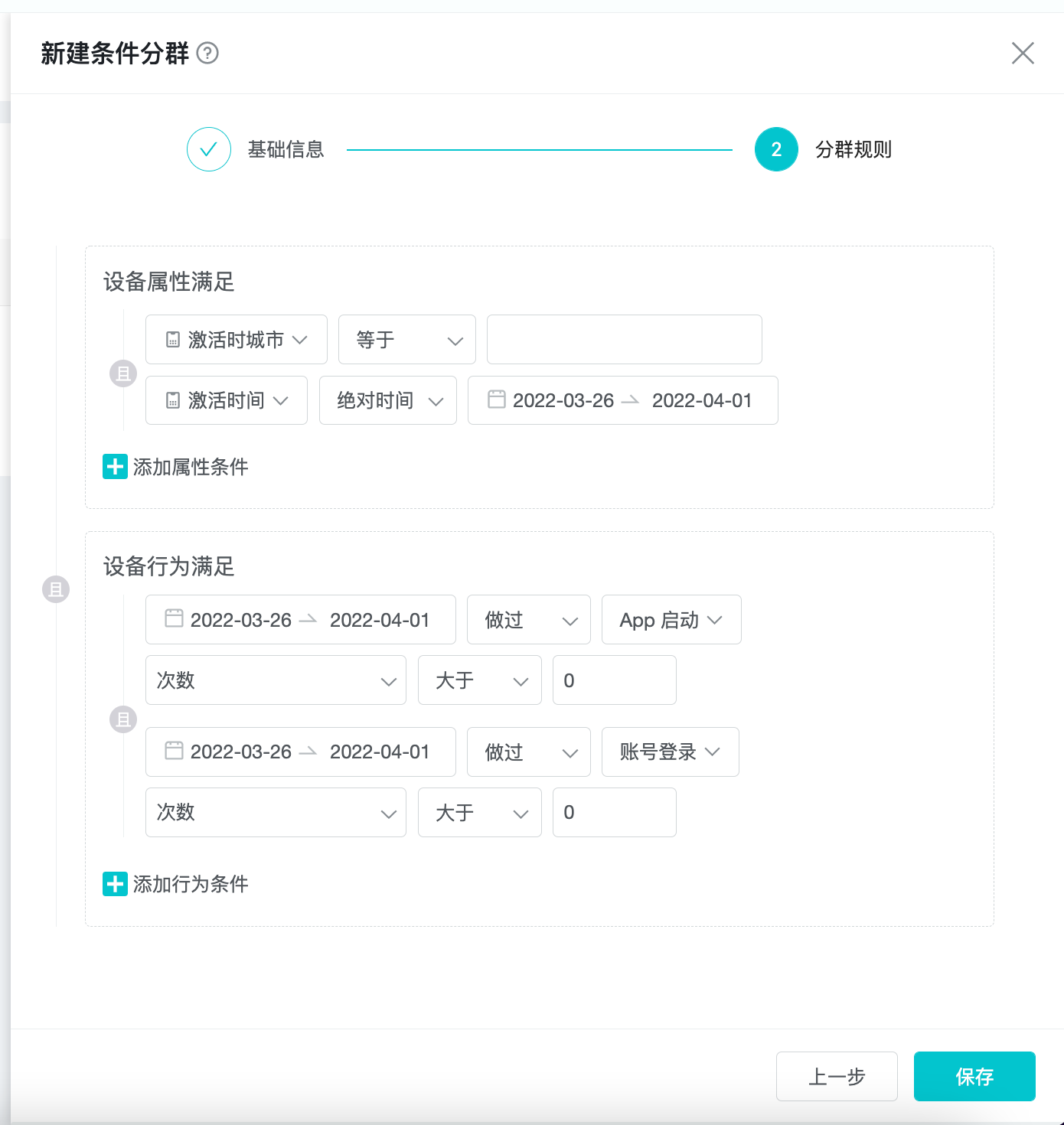
在「分群规则」页,规则分为「属性」、「行为」两部分,两部分之间可以切换「且或」关系。
在「属性」规则部分,基于选择的分群主体,设置相应的属性条件,各个属性条件可以切换「且或」关系。
在「行为」规则部分,可分为「未做过事件」、「做过事件」两类,两类条件均可多次添加,行为条件可以切换「且或」关系。
「未做过事件」即,用户在选定的时间段内,未做过该行为。
「做过事件」即,用户在选定的事件段内,做过该行为,同时可以对行为发生的结果进行筛选。
3.2 ID 分群
点击分群列表右上角的新建分群,选择「新建 ID 分群」。
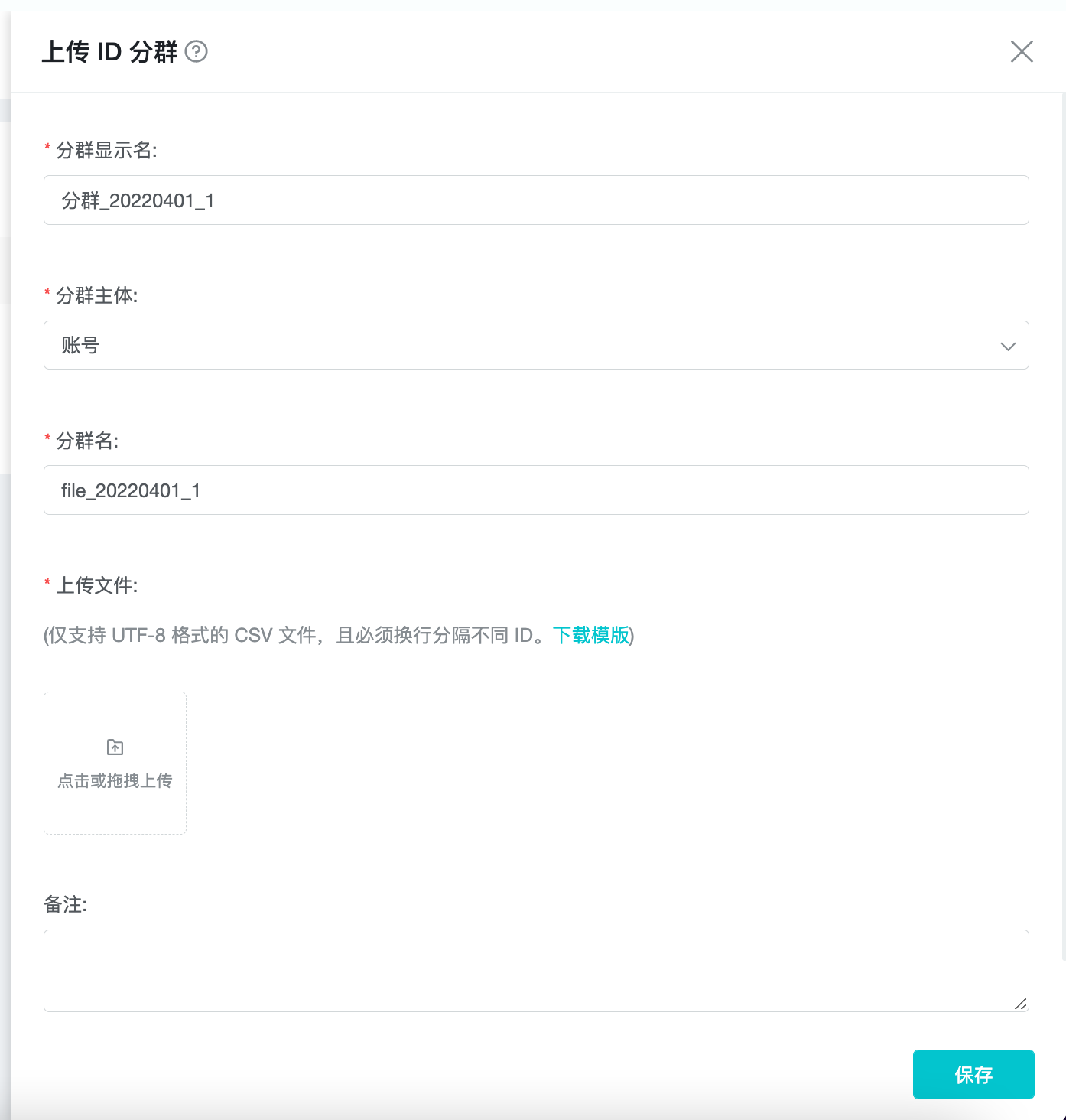
「分群名、分群主体、分群代码」与条件分群相同,不再赘述。
在新建 ID 分群页,上传 ID 文件,系统将把文件中的 ID 按照选择的「分群主体」与系统中已有的用户数据进行关联,找到符合条件的用户。
文件格式要求:ID 文件中每一行记录一个 ID 字段,使用 UTF-8 编码的 CSV 文本格式记录。若上传内容中存在未匹配项(即项目中不存在 ID 对应的用户),则该项会直接跳过,不会被纳入分群中。可下载模板作为参考。
3.3 结果分群
在各个分析模型中,如果指标是用户数(如事件分析中的「触发用户数」、留存或漏斗分析中某环节的留存或流失用户),则在结果报表中可点击「创建结果分群」来创建分群。
创建分群时,可设置结果分群的名称以及备注,形成对结果分群的描述。
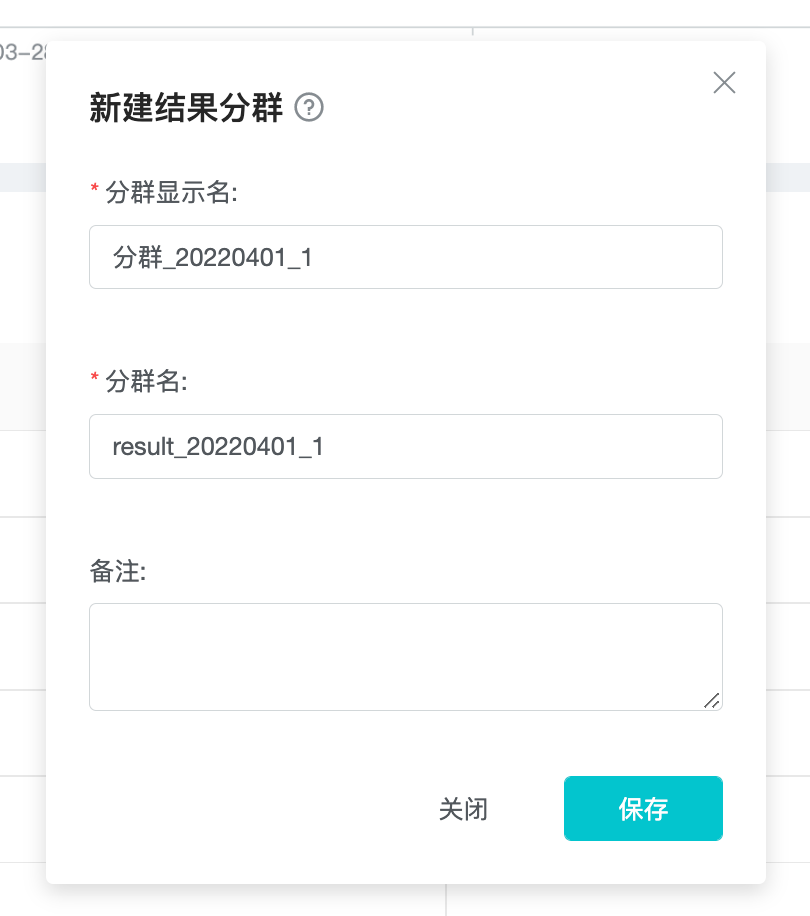
结果分群不能修改创建规则以及更新,只能修改分群的名称以及备注。
4. 对用户分群的各类操作
创建的分群会以列表形式展示在用户分群页

用户可以对分群进行查看、编辑、删除、更新、下载、复制操作,如下:
| 操作 | 位置 | 效果 |
|---|---|---|
| 查看 | 分群名 | 查看分群详情 |
| 编辑 | 操作栏 | 进入编辑分群弹窗 |
| 删除 | 操作栏 | 删除分群 |
| 更新 | 操作栏 | 手动启动分群计算,并更新分群结果 |
| 下载 | 操作栏 | 下载当前分群结果的用户列表 |
| 复制 | 操作栏 | 新建一个与当前各参数相同的分群 |
5. 使用用户分群
5.1 聚焦或排除部分用户
聚焦符合特定条件的高价值用户,如:付费金额大于 100 的用户,从而在分析模型中对强付费能力用户进行定向分析,了解其行为特征;
排除符合特定条件的可疑用户,如:在同一设备上活跃过 3 个账号以上的设备,从而将可以的工作室设备进行排除,不再对正常用户的分析结果。
5.2 用户数据导入与输出
将外部用户数据导入系统创建分群,如:公司在其他游戏项目中已有一批高付费能力的用户、设备,因此可将其导入,探索其在本项目中的活跃、付费情况,更好的引导潜在高付费用户的付费。
下载分群结果作为其他系统的操作依据,如:导出疑似工作室设备、账号,从而在游戏运营系统中,对其进行处罚、封禁。
5.3 分析结果的下钻分析
结果分群基于分析模型的结果报表,因而非常适合作为下钻分析的基础。
例如,通过漏斗分析计算用户浏览商品、发起订单、支付订单的漏斗转化情况,发现大量用户在发起订单后便流失了。此时便可对该步骤的流失用户进行结果分群,通过各分析模型分析该分群用户的各属性、行为,探索其发起订单但却未成功支付的原因。