存储 REST API
REST API 可以让你用任何支持发送 HTTP 请求的设备来与云服务进行交互,你可以使用 REST API 做很多事情,比如:
- 使用任何编程语言操作云端数据。
- 如果你不再需要使用云服务,你可以导出你所有的数据。
- 一个追求最少化依赖库的应用可以不引入 SDK,直接访问 REST API 获取云服务上的数据。
- 你可以批量新增大量数据,供应用之后读取。
- 你可以下载最近的数据用于离线分析和归档备份。
API 版本
当前的 API 版本是 1.1。
在线测试
为了方便测试 REST API,文档给出了 curl 命令示例,示例针对类 unix 平台(macOS、Linux 等)编写,直接粘贴至 Windows 平台 cmd.exe 很可能无法工作。
例如,curl 命令示例中的 shell 换行符(\)在 cmd.exe 中是目录分隔符。
Windows 平台建议使用 Postman 等客户端测试。
点击展开 Postman 示例
Postman 可直接导入 curl 命令。
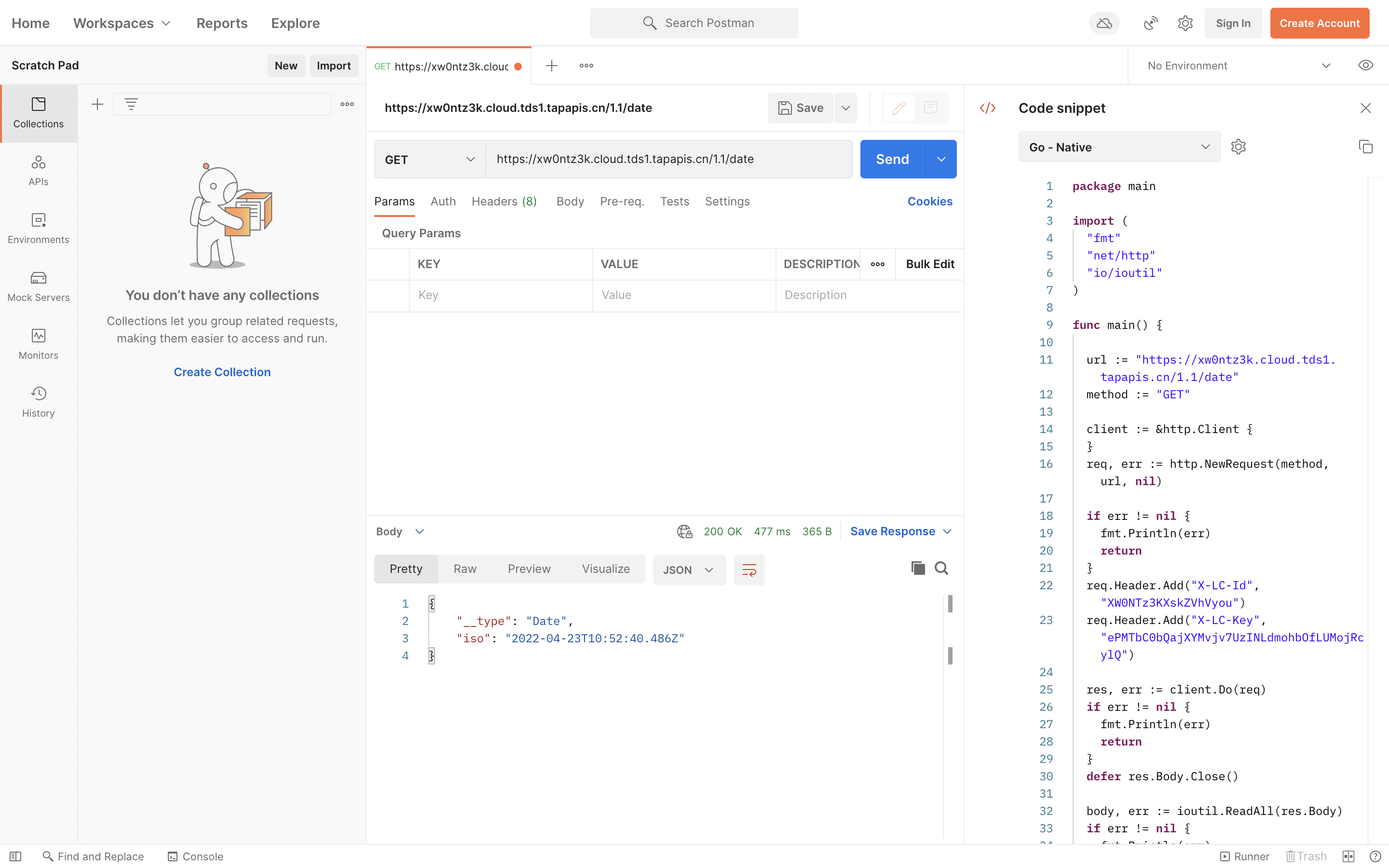
Postman 还支持自动生成多种语言(库)调用 REST API 的代码。
Base URL
REST API 请求的 Base URL(下文 curl 示例中用 {{host}} 表示)即应用绑定的 API 自定义域名,可以在 开发者中心 > 你的游戏 > 游戏服务 > 应用配置 > 域名配置 绑定、查看。
详见文档关于域名的说明。
对象
| URL | HTTP | 功能 |
|---|---|---|
| /1.1/classes/<className> | POST | 创建对象 |
| /1.1/classes/<className>/<objectId> | GET | 获取对象 |
| /1.1/classes/<className>/<objectId> | PUT | 更新对象 |
| /1.1/classes/<className> | GET | 查询对象 |
| /1.1/classes/<className>/<objectId> | DELETE | 删除对象 |
| /1.1/scan/classes/<className> | GET | 按照特定顺序遍历 Class |
角色
| URL | HTTP | 功能 |
|---|---|---|
| /1.1/roles | POST | 创建角色 |
| /1.1/roles/<objectId> | GET | 获取角色 |
| /1.1/roles/<objectId> | PUT | 更新角色 |
| /1.1/roles | GET | 查询角色 |
| /1.1/roles/<objectId> | DELETE | 删除角色 |
数据 Schema
| URL | HTTP | 功能 |
|---|---|---|
| /1.1/schemas | GET | 获取应用所有 Class 的 Schema |
| /1.1/schemas/<className> | GET | 获取应用指定 Class 的 Schema |
其他 API
| URL | HTTP | 功能 |
|---|---|---|
| /1.1/date | GET | 获得服务端当前时间 |
| /1.1/exportData | POST | 请求导出应用数据 |
| /1.1/exportData/<id> | GET | 获取导出数据任务状态和结果 |
应用凭证
在 开发者中心 > 你的游戏 > 游戏服务 > 应用配置 可以查看应用的基本信息:
- Client ID:又称
App ID,在 SDK 初始化时用到。 - Client Token:又称
App Key,客户端对服务端的调用凭证,在 SDK 初始化时用到。 - 域名配置 > 云服务 API:又称 API 域名或 Server URL,在客户端 SDK 初始化时用到。域名配置参考下一节域名。
- Server Secret��:又称
Master Key,用于在自有服务器、云引擎等受信任环境调用管理接口,具备跳过一切权限验证的超级权限。所以一定注意保密,千万不要在客户端代码中使用该凭证。
请求格式
对于 POST 和 PUT 请求,请求的主体必须是 JSON 格式,而且 HTTP header 的 Content-Type 需要设置为 application/json。
用户验证通过 HTTP header 来进行,X-LC-Id 标明正在运行的是哪个应用(应用的 App ID,对应到开发者中心游戏的 Client ID),X-LC-Key 用来授权鉴定 endpoint:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"content": "更新一篇博客的内容"}' \
https://{{host}}/1.1/classes/Post/<objectId>
X-LC-Key 通常情况下是应用的 App Key(对应到开发者中心游戏的 Client Token),有些情况(需要超级权限的操作)下是应用的 Master Key(对应到开发者中心游戏的 Server Secret)。
当 X-LC-Key 值为 Master Key 时,需要在其后添加 ,master 后缀以示区分,例如:
X-LC-Key: {{masterkey}},master
对于 JavaScript 使用,云服务支持跨域资源共享,所以你可以将这些 header 同 XMLHttpRequest 一同使用。
REST API 通讯支持 gzip 和 brotli 压缩,客户端可以通过指定相应的 Accept-Encoding HTTP 头开启压缩。
更安全的鉴权方式
我们还支持一种新的 API 鉴权方式,即在 HTTP header 中使用 X-LC-Sign 来代替 X-LC-Key,以降低 App Key 的泄露风险。例如:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Sign: d5bcbb897e19b2f6633c716dfdfaf9be,1453014943466" \
-H "Content-Type: application/json" \
-d '{"content": "在 HTTP header 中使用 X-LC-Sign 来更新一篇博客的内容"}' \
https://{{host}}/1.1/classes/Post/<objectId>
X-LC-Sign 的值是由 sign,timestamp[,master] 组成的字符串:
| 取值 | 约束 | 描述 |
|---|---|---|
| sign | 必须 | 将 timestamp 加上 App Key 或 Master Key 组成的字符串,再对它做 MD5 签名后的结果。 |
| timestamp | 必须 | 客户端产生本次请求的 unix 时间戳(UTC),精确到毫秒。 |
| master | 可选 | 字符串 "master",当使用 master key 签名请求的时候,必须加上这个后缀明确说明是使用 master key。 |
注意,sign 中的 MD5 签名的 hex 值中的字母请使用小写。如果使用大写字母,会导致签名校验失败。
举例来说,假设应用的信息如下:
| App Id | FFnN2hso42Wego3pWq4X5qlu |
| App Key | UtOCzqb67d3sN12Kts4URwy8 |
| Master Key | DyJegPlemooo4X1tg94gQkw1 |
| 请求时间 | 2016-01-17 15:15:43.466 GMT+08:00 |
| timestamp | 1453014943466 |
使用 App Key 来计算 sign:
md5( timestamp + App Key )
= md5(1453014943466UtOCzqb67d3sN12Kts4URwy8)
= d5bcbb897e19b2f6633c716dfdfaf9be
-H "X-LC-Sign: d5bcbb897e19b2f6633c716dfdfaf9be,1453014943466" \
使用 Master Key 来计算 sign:
md5( timestamp + Master Key )
= md5(1453014943466DyJegPlemooo4X1tg94gQkw1)
= e074720658078c898aa0d4b1b82bdf4b
-H "X-LC-Sign: e074720658078c898aa0d4b1b82bdf4b,1453014943466,master" \
(最后加上 ,master 来告诉服务器这个签名是使用 master key 生成的。)
使用 master key 将绕过所有权限校验,应该确保只在可控环境中使用,比如自行开发的管理平台,并且要完全避免泄露。 以上两种计算 sign 的方法可以根据实际情况来选择一种使用。
指定 hook 函数调用环境
请求可能触发云引擎的 hook 函数,可以通过设置 HTTP 头 X-LC-Prod 来区分调用的环境。
X-LC-Prod: 0表示调用预备环境X-LC-Prod: 1表示调用生产环境
默认(未指定 X-LC-Prod 头)调用生产环境的 hook 函数。
响应格式
对于所有的请求,响应格式都是一个 JSON 对象。
一个请求是否成功是由 HTTP 状态码标明的。一个 2XX 的状态码表示成功,而一个 4XX 表示请求失败。当一个请求失败时响应的主体仍然是一个 JSON 对象,但是总是会包含 code 和 error 这两个字段,你可以用它们来进行调试。举个例子,如果尝试用非法的属性名来保存一个对象会得到如下信息:
{
"code": 105,
"error": "Invalid key name. Keys are case-sensitive and 'a-zA-Z0-9_' are the only valid characters. The column is: 'invalid?'."
}
对象
对象格式
数据存储服务是建立在 LCObject(对象)基础上的,每个 LCObject 包含若干属性值对(key-value,也称「键值对」),属性的值是与 JSON 格式兼容的数据。 通过 REST API 保存对象需要将对象的数据通过 JSON 来编码。这个数据是无模式化的(schema free),这意味着你不需要提前标注每个对象上有哪些 key,你只需要随意设置键值对就可以,后端会保存它。
举个例子,假如我们要实现一个类似于微博的社交 App,主要有三类数据:账户、帖子、评论,一条微博帖子可能包含下面几个属性:
{
"content": "每个 Java 程序员必备的 8 个开发工具",
"pubUser": "官方客服",
"pubTimestamp": 1435541999
}
Key(属性名)必须是字母、数字、下划线组成的字符串,Value(属性值)可以是任何可以 JSON 编码的数据。
每个对象都有一个类名,你可以通过类名来区分不同的数据。例如,我们可以把微博的帖子对象称之为 Post。我们建议将类和属性名分别按照 NameYourClassesLikeThis 和 nameYourKeysLikeThis 这样的惯例来命名,即区分第一个字母的大小写,这样可以提高代码的可读性和可维护性。
当你从云端获取对象时,一些字段会被自动加上,如 createdAt、updatedAt 和 objectId。这些字段的名字是保留的,值也不允许修改。我们上面设置的对象在获取时应该是下面的样子:
{
"content": "每个 Java 程序员必备的 8 个开发工具",
"pubUser": "官方客服",
"pubTimestamp": 1435541999,
"createdAt": "2015-06-29T01:39:35.931Z",
"updatedAt": "2015-06-29T01:39:35.931Z",
"objectId": "558e20cbe4b060308e3eb36c"
}
createdAt 和 updatedAt 都是 UTC 时间戳,以 ISO 8601 标准和毫秒级精度储存:YYYY-MM-DDTHH:MM:SS.MMMZ。objectId 是一个字符串,在类中可以唯一标识一个实例。
在 REST API 中,class 级的操作都是通过一个带类名的资源路径(URL)来标识的。例如,如果类名是 Post,那么 class 的 URL 就是:
https://{{host}}/1.1/classes/Post
对于用户账户这种对象,有一个特殊的 URL:
https://{{host}}/1.1/users
针对于一个特定的对象的操作可以通过组织一个 URL 来做。例如,对 Post 中的一个 objectId 为 558e20cbe4b060308e3eb36c 的对象的操作应使用如下 URL:
https://{{host}}/1.1/classes/Post/558e20cbe4b060308e3eb36c
创建对象
创建一个新的对象,应该向 class 的 URL 发送一个 POST 请求,其中应该包含对象本身。 例如,要创建如上所说的对象:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"content": "每个 Java 程序员必备的 8 个开发工具","pubUser": "官方客服","pubTimestamp": 1435541999}' \
https://{{host}}/1.1/classes/Post
当创建成功时,HTTP 的返回是 201 Created,而 header 中的 Location 表示新的 object 的 URL:
Status: 201 Created
Location: https://{{host}}/1.1/classes/Post/558e20cbe4b060308e3eb36c
响应的主体是一个 JSON 对象,包含新的对象的 objectId 和 createdAt 时间戳。
{
"createdAt": "2015-06-29T01:39:35.931Z",
"objectId": "558e20cbe4b060308e3eb36c"
}
如果希望返回新创建的对象的完整信息,可以在 URL 里加上 fetchWhenSave 选项,并且设置为 true:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"content": "每个 Java 程序员必备的 8 个开发工具","pubUser": "官方客服","pubTimestamp": 1435541999}' \
https://{{host}}/1.1/classes/Post?fetchWhenSave=true
Class 名称只能包含字母、数字、下划线。 **每个应用最多可以创建 500 个 class,每个 class 最多包含 300 个字段,**但每个 class 中的记录数量没有限制。
获取对象
当你创建了一个对象时,你可以通过发送一个 GET 请求到返回的 header 的 Location 以获取它的内容。例如,为了得到我们上面创建的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/classes/Post/558e20cbe4b060308e3eb36c
返回的主体是一个 JSON 对象包含所有用户提供的 field 加上 createdAt、updatedAt 和 objectId 字段:
{
"content": "每个 Java 程序员必备的 8 个开发工具",
"pubUser": "官方客服",
"pubTimestamp": 1435541999,
"createdAt": "2015-06-29T01:39:35.931Z",
"updatedAt": "2015-06-29T01:39:35.931Z",
"objectId": "558e20cbe4b060308e3eb36c"
}
当获取的对象有指向其子对象的指针时,你可以加入 include 选项来获取这些子对象。假设微博记录中有一个字段 author 来指向发布者的账户信息,按上面的例子,可以这样来连带获取发布者完整信息:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'include=author' \
https://{{host}}/1.1/classes/Post/<objectId>
include 支持点号,例如,假定发布者有一个字段 department 指向发布者所属的部门,那么可以使用 include=author.department 一并获取部门信息。
类不存在时,返回 404 Not Found 错误:
{
"code": 101,
"error": "Class or object doesn't exists."
}
objectId 不存在时,返回一个空对象(HTTP 状态码为 200 OK):
{}
某些特殊的系统内置类(类名以下划线开头),objectId 不存在时不一定返回空对象。
例如,查询 _User 时,objectId 不存在会返回 400 Bad Request 错误:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/classes/_User/<NonexistObjectId>
返回:
{
"code": 211,
"error": "Could not find user."
}
顺带提一下,获取用户推荐使用 GET /users/<objectId>��,而不是直接查询 _User 类。
参见后文获取用户一节。
更新对象
为了更改一个对象已经有的数据,你可以发送一个 PUT 请求到对象相应的 URL 上,任何你未指定的 key 都不会更改,所以你可以只更新对象数据的一个子集。例如,我们来更改我们对象的一个 content 字段:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"content": "每个 JavaScript 程序员必备的 8 个开发工具:http://buzzorange.com/techorange/2015/03/03/9-javascript-ide-editor/"}' \
https://{{host}}/1.1/classes/Post/<objectId>
返回的 JSON 对象只会包含一个 updatedAt 字段,表明更新发生的时间:
{
"updatedAt": "2015-06-30T18:02:52.248Z"
}
fetchWhenSave 选项对更新对象也同样有效。
但和创建对象不同,用于更新对象时仅返回更新的字段,而非全部字段。
计数器
比如一条微博,我们需要记录有多少人喜欢或者转发了它,但可能很多次喜欢都是同时发生的,如果每个客户端都直接把读到的计数值更改之后再写回去,那么极容易引发冲突和覆盖,导致最终结果不准。 云服务提供了对数字类型字段进行原子增加或者减少的功能,稳妥地实现对计数器类型数据的更新:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"upvotes":{"__op":"Increment","amount":1}}' \
https://{{host}}/1.1/classes/Post/<objectId>
这样就将对象的 upvotes 属性值(被用户点赞的次数)加上 1,其中 amount 为递增的数字大小,如果为负数,则为递减。
除了 Increment,我们也提供了 Decrement 用于递减,等价于 Increment 一个负数。
注意,虽然原子增减支持浮点数,但因为底层数据库的浮点数存储格式限制,会有舍入误差。
因此,需要原子增减的字段建议使用整数以避免误差,例如 3.14 可以存储为 314,然后在客户端进行相应的转换。
否则,以比较大小为条件查询对象的时候,需要特殊处理,
< a 需改查 < a + e,> a 需改查 > a - e,== a 需改查 > a - e 且 < a + e,其中 e 为误差范围,据所需精度取值,比如 0.0001。
位运算
如果数据表的某一列是整型,可以使用位运算操作符该列进行原子的位运算:
- BitAnd 与运算
- BitOr 或运算
- BitXor 异或运算
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"flags":{"__op":"BitOr","value": 0x0000000000000004}}' \
https://{{host}}/1.1/classes/Post/<objectId>
数组
有 3 种原子性操作可用于存储和更改数组类型的字段:
- Add:在一个数组字段的后面添加一些指定的对象(包装在一个数组内)
- AddUnique:只会在数组内原本没有这个对象的情形下才会添加入数组,插入的位置不定。
- Remove:从一个数组内移除所有的指定的对象
每种操作都有一个 key objects,其值为被添加或删除的对象列表。例如为每条微博增加一个「标签」属性 tags,然后往里面加入一些值:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"tags":{"__op":"AddUnique","objects":["Frontend","JavaScript"]}}' \
https://{{host}}/1.1/classes/Post/<objectId>
有条件更新对象
假设从某个账户对象 Account 的余额中扣除一定金额,但是要求余额要大于等于被扣除的金额才允许操作,那么就需要通过 where 参数为更新操作加上限定条件 balance >= amount:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"balance":{"__op":"Decrement","amount": 30}}' \
"https://{{host}}/1.1/classes/Account/558e20cbe4b060308e3eb36c?where=%7B%22balance%22%3A%7B%22%24gte%22%3A%2030%7D%7D"
URL 中 where 参数的值是 %7B%22balance%22%3A%7B%22%24gte%22%3A%2030%7D%7D,其实这是 {"balance":{"$gte": 30}} 被 URL 编码后的结果。
如果条件不满足,更新将失败,同��时返回错误码 305:
{
"code": 305,
"error": "No effect on updating/deleting a document."
}
特别强调:where 一定要作为 URL 的 Query Parameters 传入。
__op 操作汇总
使用 __op("操作名称", {JSON 参数}) 函数可以完成原子性操作,确保数据的一致性。
| 操作 | 说明 | 示例 |
|---|---|---|
| Delete | 删除对象的一个属性 | __op('Delete', {'delete': true}) |
| Add | 在数组末尾添加对象 | __op('Add',{'objects':['Apple','Google']}) |
| AddUnique | 在数组末尾添加不会重复的对象,插入位置不定 | __op('AddUnique', {'objects':['Apple','Google']}) |
| Remove | 从数组中删除对象 | __op('Remove',{'objects':['Apple','Google']}) |
| AddRelation | 添加一个关系 | __op('AddRelation', {'objects':[pointer('_User','558e20cbe4b060308e3eb36c')]}) |
| RemoveRelation | 删除一个关系 | __op('RemoveRelation', {'objects':[pointer('_User','558e20cbe4b060308e3eb36c')]}) |
| Increment | 递增 | __op('Increment', {'amount': 50}) |
| Decrement | 递减 | __op('Decrement', {'amount': 50}) |
| BitAnd | 与运算 | __op('BitAnd', {'value': 0x0000000000000004}) |
| BitOr | 或运算 | __op('BitOr', {'value': 0x0000000000000004}) |
| BitXor | 异或运算 | __op('BitXor', {'value': 0x0000000000000004}) |
删除对象
要在云端删除一个对象,可以发送一个 DELETE 请求到指定的对象的 URL,比如:
curl -X DELETE \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/classes/Post/<objectId>
还可以使用 Delete 操作删除一个对象的一个字段(注意此时 HTTP Method 是 PUT):
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"downvotes":{"__op":"Delete"}}' \
https://{{host}}/1.1/classes/Post/<objectId>
有条件删除对象
为请求增加 where 参数即可以按指定的条件来删除对象。例如删除点击量 clicks 为 0 的帖子:
curl -X DELETE \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
"https://{{host}}/1.1/classes/Post/<objectId>?where=%7B%22clicks%22%3A%200%7D"
URL 中 where 参数的值是 %7B%22clicks%22%3A%200%7D,其实这是 {"clicks": 0} 被 URL 编码后的结果。
如果条件不满足,删除将失败,同时返回错误码 305:
{
"code": 305,
"error": "No effect on updating/deleting a document."
}
特别强调:where 一定要作为 URL 的 Query Parameters 传入。
遍历 Class
因为更新和删除都是基于单个对象的,都要求提供 objectId,但是有时候用户需要高效地遍历一个 Class,做一些批量的更新或者删除的操作。
通常情况下,如果 Class 的数量规模不大,使用查询加上 skip 和 limit 分页配合排序 order 就可以遍历所有数据。
但是当 Class 数量规模比较大的时候, skip 的效率就非常低了(这跟 MySQL 等关系数据库的原因一样,深度翻页比较慢)。
为了避免性能问题,这种情况下可以通过指定 createdAt 或 updatedAt 的范围来实现翻页。
我们还额外提供了 scan 接口,可以按照特定字段排序来高效地遍历一张表,相比指定 createdAt 或 updatedAt 范围来翻页的写法也更加直截了当。
默认情况下,按 objectId 升序,同时支持设置 limit 限定每一批次的返回数量,默认 limit 为 100,最大可设置为 1000:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-G \
--data-urlencode 'limit=10' \
https://{{host}}/1.1/scan/classes/Article
scan 强制要求使用 MasterKey。
返回:
{
"results": [
{
"tags": ["clojure", "\u7b97\u6cd5"],
"createdAt": "2016-07-07T08:54:13.250Z",
"updatedAt": "2016-07-07T08:54:50.268Z",
"title": "clojure persistent vector",
"objectId": "577e18b50a2b580057469a5e"
}
//...
],
"cursor": "pQRhIrac3AEpLzCA"
}
其中 results 对应的就是返回的对象列表,而 cursor 表示本次遍历当前位置的「指针」,当 cursor 为 null 的时候,表示已经遍历完成,如果不为 null,请继续传入 cursor 到 scan 接口就可以从上次到达的位置继续往后查找:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-G \
--data-urlencode 'limit=10' \
--data-urlencode 'cursor=pQRhIrac3AEpLzCA' \
https://{{host}}/1.1/scan/classes/Article
每次返回的 cursor 的有效期是 10 分钟。
遍历还支持过滤条件,加入 where 参数:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-G \
--data-urlencode 'limit=10' \
--data-urlencode 'where={"score": 100}' \
https://{{host}}/1.1/scan/classes/Article
默认情况下系统按 objectId 升序排序,增加 scan_key 参数可以使用其他字段来排序:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-G \
--data-urlencode 'limit=10' \
--data-urlencode 'scan_key=score' \
https://{{host}}/1.1/scan/classes/Article
scan_key 也支持倒序,前面加个减号即可,例如 -score。
自定义的 scan_key 需要满足严格单调递增的条件,并且 scan_key 不可作为 where 查询条件存在。
scan 不支持 include 参数,调用 scan 时传入 include 参数是未定义行为。
如果遍历 Class 时需要使用 include 参数,请使用普通的查询,并通过指定 createdAt 或 updatedAt 的范围来实现翻页。
批量操作
为了减少网络交互的次数太多带来的时间浪费,你可以在一个请求中对多个对象进行 create、update、delete 操作。
在一个批次中每一个操作都有相应的方法、路径和主体,这些参数可以代替你通常会使用的 HTTP 方法。这些操作会以发送过去的顺序来执行,比如我们要一次发布一系列的微博:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"requests": [
{
"method": "POST",
"path": "/1.1/classes/Post",
"body": {
"content": "2021 年 5 月 1 日至 2021 年 5 月 5 日放假五天,5 月 8 日调休正常上班。",
"pubUser": "官方客服"
}
},
{
"method": "POST",
"path": "/1.1/classes/Post",
"body": {
"content": "我们将于 2021 年 2 月 10 日至 2021 年 2 月 17 日放假八天,2 月 18 日恢复正常工作,放假期间,运维团队仍将在线值班,以应对可能的突发情况,保障服务稳定。",
"pubUser": "官方客服"
}
}
]
}' \
https://{{host}}/1.1/batch
我们对每一批次中所包含的操作数量(requests 数组中的元素个数)暂不设限,但考虑到云端对每次请求的 body 内容大小有 20 MB 的限制,因此建议将每一批次的操作数量控制在 100 以内。
批量操作的响应 body 会是一个列表,列表的元素数量和顺序与给定的操作请求是一致的。每一个在列表中的元素都有一个字段是 success 或者 error。
[
{
"error": {
"code": 1,
"error": "Could not find object by id '558e20cbe4b060308e3eb36c' for class 'Post'."
}
},
{
"success": {
"updatedAt": "2017-02-22T06:35:29.419Z",
"objectId": "58ad2e850ce463006b217888"
}
}
]
需要注意,即使一个 batch 请求返回的响应码为 200,这仅代表服务端已收到并处理了这个请求,但并不说明该 batch 中的所有操作都成功完成,只有当返回 body 的列表中不存在 error 元素,开发者才可以认为所有操作都已成功完成。
在 batch 操作中 update 和 delete 同样是有效的:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"requests": [
{
"method": "PUT",
"path": "/1.1/classes/Post/55a39634e4b0ed48f0c1845b",
"body": {
"upvotes": 2
}
},
{
"method": "DELETE",
"path": "/1.1/classes/Post/55a39634e4b0ed48f0c1845c"
}
]
}' \
https://{{host}}/1.1/batch
批量操作还有一个冷门用途,代替 URL 过长的 GET(比如使用 containedIn 等方法构造查询)和 DELETE (比如批量删除)请求,以绕过服务端和某些客户端对 URL 长度的限制。
数据类型
到现在为止我们只使用了可以被标准 JSON 编码的值,客户端 SDK 同样支持日期、二进制数据和关系型数据。在 REST API 中,这些值都被编码了,同时有一个 __type 字段(注意:前缀是两个下划线)来标示出它们的类型,所以如果你采用正确的编码的话就可以读或者写这些字段。
Date 类型包含了一个 iso 字段,其值是一个 UTC 时间戳,以 ISO 8601 格式和毫秒级的精度来存储的时间值,格式为:YYYY-MM-DDTHH:MM:SS.MMMZ:
{
"__type": "Date",
"iso": "2015-06-21T18:02:52.249Z"
}
Date 和内置的 createdAt 字段和 updatedAt 字段相结合的时候特别有用,举个例子:为了找到在一个特殊时间发布的微博,只需要将 Date 编码后放在使用了比较条件的查询里面:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"createdAt":{"$gte":{"__type":"Date","iso":"2015-06-21T18:02:52.249Z"}}}' \
https://{{host}}/1.1/classes/Post
注意,由于 createdAt 和 updatedAt 属于保留字段,因此通过 REST API 请求这两个字段时,将直接返回 UTC 时间戳字符串。
Byte 类型包含了一个 base64 字段,这个字段是一些二进制数据编码过的 base64 字符串。base64 是 MIME 使用的标准,不包含空白符:
{
"__type": "Bytes",
"base64": "5b6I5aSa55So5oi36KGo56S65b6I5Zac5qyi5oiR5Lus55qE5paH5qGj6aOO5qC877yM5oiR5Lus5bey5bCGIExlYW5DbG91ZCDmiYDmnInmlofmoaPnmoQgTWFya2Rvd24g5qC85byP55qE5rqQ56CB5byA5pS+5Ye65p2l44CC"
}
Pointer 类型是用来设定 LCObject 作为另一个对象的值时使用的,它包含了 className 和 objectId 两个属性值,用来提取目标对象:
{
"__type": "Pointer",
"className": "Post",
"objectId": "55a39634e4b0ed48f0c1845c"
}
指向用户对象的 Pointer 的 className 为 _User,前面加一个下划线表示开发者不能定义的类名,而且所指的类是内置的。
类似地,指向角色和 Installation 的 Pointer 的 className 为 _Role 和 _Installation。
然而,关联文件(可以看成指向文件的 Pointer)采用不同于 Pointer 的编码形式:
{
"id": "543cbaede4b07db196f50f3c",
"__type": "File"
}
GeoPoint 包含地理位置的经纬度:
{
"__type": "GeoPoint",
"latitude": 39.9,
"longitude": 116.4
}
当更多的数据类型被加入的时候,它们都会采用 hashmap 加上一个 __type 字段的形式,所以你不应该使用 __type 作为你自己的 JSON 对象的 key。
查询
基础查询
通过发送一个 GET 请求到类的 URL 上,不需要任何 URL 参数,你就可以一次获取多个对象。下面就是简单地获取所有微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
https://{{host}}/1.1/classes/Post
返回的值就是一个 JSON 对象包含了 results 字段,它的值就是对象的列表:
{
"results": [
{
"content": "2021 年 5 月 1 日至 2021 年 5 月 5 日放假五天,5 月 8 日调休正常上班。",
"pubUser": "官方客服",
"upvotes": 2,
"createdAt": "2015-06-29T03:43:35.931Z",
"objectId": "55a39634e4b0ed48f0c1845b"
},
{
"content": "我们将于 2021 年 2 月 10 日至 2021 年 2 月 17 日放假八天,2 月 18 日恢复正常工作,放假期间,运维团队仍将在线值班,以应对可能的突发情况,保障服务稳定。",
"pubUser": "官方客服",
"pubTimestamp": 1435541999,
"createdAt": "2015-06-29T01:39:35.931Z",
"updatedAt": "2015-06-29T01:39:35.931Z",
"objectId": "558e20cbe4b060308e3eb36c"
}
]
}
- 控制台对
createdAt和updatedAt的展示做了优化,它们会依据用户操作系统时区而显示为本地时间; - 客户端 SDK 获取到这些时间后也会将其转换为本地时间;
- 通过 REST API 获取到的则是原始的 UTC 时间,开发者可能需要根据情况做相应的时区转换。
查询约束
通过 where 参数的形式可以对查询对象做出约束。
where 参数的值应该是 JSON 编码过的。就是说,如果你查看真正被发出的 URL 请求,它应该是先被 JSON 编码过,然后又被 URL 编码过。最简单的使用 where 参数的方式就是包含应有的 key 和 value。例如,如果我们想要看到「官方客服」发布的所有微博,我们应该这样构造查询:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"pubUser":"官方客服"}' \
https://{{host}}/1.1/classes/Post
除了完全匹配一个给定的值以外,where 也支持比较的方式,而且它还支持对 key 的一些 hash 操作,比如包含。where 参数支持如下选项:
| Key | Operation |
|---|---|
$ne | 不等于 |
$lt | 小于 |
$lte | 小于等于 |
$gt | 大于 |
$gte | 大于等于 |
$regex | 正则表达式;$options 指定全局修饰符 |
$in | 包含任意一个数组值 |
$nin | 不包含任意一个数组值 |
$all | 包括所有的数组值 |
$exists | 指定 Key 有值 |
$select | 匹配另一个查询的返回值 |
$dontSelect | 排除另一个��查询的返回值 |
例如获取在 2015-06-29 当天发布的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"createdAt":{"$gte":{"__type":"Date","iso":"2015-06-29T00:00:00.000Z"},"$lt":{"__type":"Date","iso":"2015-06-30T00:00:00.000Z"}}}' \
https://{{host}}/1.1/classes/Post
求点赞次数少于 10 次,且该次数还是奇数的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"upvotes":{"$in":[1,3,5,7,9]}}' \
https://{{host}}/1.1/classes/Post
获取不是「官方客服」发布的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"pubUser":{"$nin":["官方客服"]}}' \
https://{{host}}/1.1/classes/Post
获取有人喜欢的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"upvotes":{"$exists":true}}' \
https://{{host}}/1.1/classes/Post
获取没有被人喜欢过的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"upvotes":{"$exists":false}}' \
https://{{host}}/1.1/classes/Post
微博有用户互相关注的功能,如果我们用 _Followee(用户关注的人) 和 _Follower(用户的粉丝) 这两个类来存储用户之间的关注关系,我们可以创建一个查询来找到某个用户关注的人发布的微博(Post 表中有一个字段 author 指向发布者):
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={
"author": {
"$select": {
"query": {
"className":"_Followee",
"where": {
"user":{
"__type": "Pointer",
"className": "_User",
"objectId": "55a39634e4b0ed48f0c1845c"
}
}
},
"key":"followee"
}
}
}' \
https://{{host}}/1.1/classes/Post
order 参数指定一个字段的排序方式,前面加一个负号表示逆序。返回 Post 记录并按发布时间升序排列:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'order=createdAt' \
https://{{host}}/1.1/classes/Post
降序排列:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'order=-createdAt' \
https://{{host}}/1.1/classes/Post
对多个字段进行排序,要使用逗号分隔的列表。将 Post 以 createdAt 升序和 pubUser 降序进行排序:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'order=createdAt,-pubUser' \
https://{{host}}/1.1/classes/Post
你可以用 limit 和 skip 来做分页。limit 的默认值是 100,任何 1 到 1000 之间的值都是可选的,在 1 到 1000 范围之外的都强制转成默认的 100。比如为了获取排序在 401 到 600 之间的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'limit=200' \
--data-urlencode 'skip=400' \
https://{{host}}/1.1/classes/Post
你可以通过传入 keys 参数和一个逗号分隔列表限定返回的字段。为了返回对象只包含 pubUser 和 content 字段(还有特殊的内置字段比如 objectId、createdAt 和 updatedAt):
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'keys=pubUser,content' \
https://{{host}}/1.1/classes/Post
keys 的参数中可以使用点号进一步限定只返回字段的部分属性,例如,只返回发布者的姓氏:keys=pubUser.familyName。
keys 还支持反向选择,也就是不返回某些字段,字段名前面加个减号即可,比如我不想查询返回 author:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'keys=-author' \
https://{{host}}/1.1/classes/Post
反向选择同样适用于内置字段,比如 keys=-createdAt,-updatedAt,-objectId。
另外反向选择同样可以和点号组合使用,例如 keys=-pubUser.createdAt,-pubUser.updatedAt。
返回 ACL 字段
默认情况下不会返回 ACL 字段。
开发者中心 > 你的游戏 > 游戏服务 > 云服务 > 数据存储 > 服务设置 > 查询设置 中勾选 查询时返回值包括 ACL,且指定了 returnACL=true 时返回结果中才会包含 ACL 字段。
所有以上这些参数都可以组合使用。
正则查询
获取标题以大写「WTO」开头的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-G \
--data-urlencode 'where={"title":{"$regex":"^WTO.*","$options":"i"}}' \
https://{{host}}/1.1/classes/Post
我们使用以下数据来演示如何使用 $options 匹配 title 字段值:
{ "_id" : 100, "title" : "Single line description." },
{ "_id" : 101, "title" : "First line\nSecond line" },
{ "_id" : 102, "title" : "Many spaces before line" },
{ "_id" : 103, "title" : "Multiple\nline description" },
{ "_id" : 104, "title" : "abc123" }
| 参数 | 说明 | 示例 |
|---|---|---|
i | 忽略大小写 | {"$regex":"single", "$options":"i"} 将匹配 |
m | 多行匹配 比如文本中包含了换行符 \n | {"$regex":"^S", "$options":"m"}(以大写字母 S 开头)将匹配
|
x | 忽略空白字符 包括空格、tab、 \n、# 注释等,但对 vertical tab(ASCII 码为 11)无效。 | {"$regex":"abc #category code\n123 #item number", "$options":"x"}(# 后面为注释)将匹配 |
s | 允许 . 匹配任意字符和换行 | {"$regex":"m.*line", "$options":"si"} 将匹配
|
以上参数可以组合使用,如 "$options":"sixm"。
数组查询
如果 key 的值是数组类型,查找 key 值中有 2 的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"arrayKey":2}' \
https://{{host}}/1.1/classes/TestObject
查找 key 值中有 2 或 3 或 4 的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"arrayKey":{"$in":[2,3,4]}}' \
https://{{host}}/1.1/classes/TestObject
使用 $all 操作符来找到 key 值中同时有 2 和 3 和 4 的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"arrayKey":{"$all":[2,3,4]}}' \
https://{{host}}/1.1/classes/TestObject
使用 $size 操作符来查找 key 值数组长度为 3 的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"arrayKey":{"$size": 3}}' \
https://{{host}}/1.1/classes/TestObject
关系查询
有几种方式来查询对象之间的关系数据。如果你想获取对象,而这个对象的一个字段对应了另一个对象,你可以用一个 where 查询,自己构造一个 Pointer,和其他数据类型一样。例如,每条微博都会有很多人评论,我们可以让每一个 Comment 将它对应的 Post 对象保存到 post 字段上,这样你可以取得一条微博下所有 Comment:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"post":{"__type":"Pointer","className":"Post","objectId":"558e20cbe4b060308e3eb36c"}}' \
https://{{host}}/1.1/classes/Comment
如果你想获取对象,这个对象的一个字段指向的对象需要另一个查询来指定,你可以使用 $inQuery 操作符。注意 limit 的默认值是 100 且最大值是 1000,这个限制同样适用于内部的查询,所以对于较大的数据集你可能需要细心地构建查询来获得期望的结果。
如上面的例子,假设每条微博还有一个 image 的字段,用来存储配图,你可以这样列出带图片的微博的评论数据:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"post":{"$inQuery":{"where":{"image":{"$exists":true}},"className":"Post"}}}' \
https://{{host}}/1.1/classes/Comment
有时候,你可能需要在一个查询之中返回多种类型,你可以通过传入字段到 include 参数中。比如,我们想获得最近的 10 篇评论,而你想同时得到它们关联的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'order=-createdAt' \
--data-urlencode 'limit=10' \
--data-urlencode 'include=post' \
https://{{host}}/1.1/classes/Comment
在返回结果中,post 字段会被展开为一个完整的对象,但 __type 仍将保持为 Pointer。
例如,不传入 include 参数的情况下,返回结果中包含的指向 Post 的 Pointer 只包含 __type、className、objectId:
{
"__type": "Pointer",
"className": "Post",
"objectId": "51e3a359e4b015ead4d95ddc"
}
传入 include=post 后,可以看到 pointer 被展开为:
{
"__type": "Pointer",
"className": "Post",
"objectId": "51e3a359e4b015ead4d95ddc",
"createdAt": "2015-06-29T09:31:20.371Z",
"updatedAt": "2015-06-29T09:31:20.371Z",
"desc": "Post 的其他字段也会一同被包含进来。"
}
你可以同样做多层的 include,这时要使用点号。如果你要 include 一个 Comment 对应的 Post 对应的 author:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'order=-createdAt' \
--data-urlencode 'limit=10' \
--data-urlencode 'include=post.author' \
https://{{host}}/1.1/classes/Comment
如果你要构建一个查询,这个查询要 include 多个类,此时用逗号分隔列表即可。
地理查询
之前我们简要介绍过 GeoPoint。
假如在发布微博的时候,我们也支持用户加上当时的位置信息(新增一个 location 字段),如果想看看指定的地点附近发生的事情,可以通过 GeoPoint 数据类型加上在查询中使用 $nearSphere 做到。获取离当前用户最近的 10 条微博应该看起来像下面这个样子:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'limit=10' \
--data-urlencode 'where={
"location": {
"$nearSphere": {
"__type": "GeoPoint",
"latitude": 39.9,
"longitude": 116.4
}
}
}' \
https://{{host}}/1.1/classes/Post
这会按照距离纬度 39.9、经度 116.4(当前用户所在位置)的远近排序返回一系列结果,第一个就是最近的对象。(注意:如果指定了 order 参数的话,它会覆盖按距离排序。)
为了限定搜索的最大距离,需要加入 $maxDistanceInMiles 和 $maxDistanceInKilometers 或者 $maxDistanceInRadians 参数来限定。比如要找的半径在 10 英里内的话:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={
"location": {
"$nearSphere": {
"__type": "GeoPoint",
"latitude": 39.9,
"longitude": 116.4
},
"$maxDistanceInMiles": 10.0
}
}' \
https://{{host}}/1.1/classes/Post
同样做查询寻找在一个特定的范围里面的对象也是可以的,为了找到在一个矩形的区域里的对象,按下面的格式加入一个约束 {"$within": {"$box": [southwestGeoPoint, northeastGeoPoint]}}。
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={
"location": {
"$within": {
"$box": [
{
"__type": "GeoPoint",
"latitude": 39.97,
"longitude": 116.33
},
{
"__type": "GeoPoint",
"latitude": 39.99,
"longitude": 116.37
}
]
}
}
}' \
https://{{host}}/1.1/classes/Post
GeoPoint 的经纬度的类型是数字,且经度需在 -180.0 到 180.0 之间,纬度需在 -90.0 到 90.0 之间。 另外,每个对象最多只能有一个类型为 GeoPoint 的属性。
文件查询
查询文件和查询一般对象基本一致。 例如,以下命令可以获取所有文件(和查询一般对象一样,默认最多返回 100 条结果):
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
https://{{host}}/1.1/classes/files
需要注意的是,内部文件(上传到文件服务的文件)的 url 字段是由云端动态生成的,其中涉及切换自定义域名的相关处理逻辑。
因此,通过 url 字段查询文件仅适用于外部文件(直接保存外部 URL 到文件服务创建的文件),内部文件请改用 key 字段(URL 中的路径)查询。
同理,调用 scan 接口遍历文件时,返回结果中的内部文件也不包含 url 字段,只包含 key 字段。
对象计数
如果你在使用 limit,或者如果返回的结果很多,你可能想要知道到底有多少对象应该返回,而不用把它们全部获得以后再计数,此时你可以使用 count 参数。举个例子,如果你仅仅是关心某个用户发布了多少条微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"pubUser":"官方客服"}' \
--data-urlencode 'count=1' \
--data-urlencode 'limit=0' \
https://{{host}}/1.1/classes/Post
因为这个 request 请求了 count 而且把 limit 设为了 0,返回的值里面只有计数,没有 results:
{
"results": [],
"count": 7
}
如果有一个非 0 的 limit 的话,则既会返回 results 也会返回 count。
复合查询
$or 操作符用于查询符合任意一种条件的对象,它的值为一个 JSON 数组。例如,查询企业账号和个人账号的微博:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"$or":[{"pubUserCertificate":{"$gt":2}},{"pubUserCertificate":{"$lt":3}}]}' \
https://{{host}}/1.1/classes/Post
任何在查询上的其他约束都会对返回的对象生效,所以你可以用 $or 对其他的查询添加约束。
$and 操作符用于查询符合全部条件的对象,它的值为一个 JSON 数组。例如查找存在 price 字段且 price != 199 的对象:
where={"$and":[{"price": {"$ne":199}},{"price":{"$exists":true}}]}
不过,查询条件表达式列表隐含 $and 操作符,所以上面的查询条件也可以改写为:
where=[{"price": {"$ne":199}},{"price":{"$exists":true}}]
实际上,由于这两个查询条件都是针对同一个字段(price)的查询,还可以进一步简化为:
where={"price": {"$ne":199, "$exists":true}}
不过,如果查询条件包含不止一个 or 查询,那就必须使用 $and 了:
where={"$and":[{"$or":[{"pubUserCertificate":{"$gt":2}},{"pubUserCertificate":{"$lt":3}}]},{"$or":[{"pubUser":"官方客服"},{"pubUser":"工程师团队"}]}]}
注意,在组合查询的子查询中不支持使用 limit、skip、order、include 等非过滤型的约束。
用户
参考 内建账户 REST API 文档。
角色
当你的应用的规模和用户基数成长时,你可能发现你需�要比 ACL 模型(针对每个用户)更加粗粒度的访问控制你的数据的方法。为了适应这种需求,云服务支持一种基于角色的权限控制方式。角色系统提供一种逻辑方法让你通过权限的方式来访问你的数据,角色是一种有名称的对象,包含了用户和其他角色。任何授予一个角色的权限隐含着授予它包含着的其他的角色相应的权限。
例如,你的应用中可能有一些类似于「主持人」的角色可以修改和删除其他用户创建的新的内容,你可能还有一些「管理员」有着与「主持人」相同的权限,但是还可以修改应用的其他全局性设置。通过给予用户这些角色,你可以保证新的用户可以做主持人或者管理员,不需要手动地授予每个资源的权限给各个用户。
我们提供一个特殊的角色(Role)类来表示这些用户组,为了设置权限用。角色有一些和其他对象不太一样的特殊字段。
| 字段 | 说明 |
|---|---|
| name | 角色的名字,这个值是必须的,而且只允许被设置一次,只要这个角色被创建了的话。角色的名字必须由字母、数字、下划线这些字符构成。这个名字可以用来标明角色而不需要它的 objectId。 |
| users | 一个指向一系列用户的关系,这些用户会继承角色的权限。 |
| roles | 一个指向一系列子角色的关系,这些子关系会继承父角色所有的权限。 |
通常来说,为了保持这些角色安全,你的移动应用不应该为角色的创建和管理负责。作为替代,角色应该是通过一个不同的网页上的界面来管理,或者手工被管理员所管理。
创建角色
创建一个新的角色与其他的对象不同的是 name 字段是必须的。角色必须指定一个 ACL,这个 ACL 必须尽量的约束严格一些,这样可以防止错误的用户修改角色。
创建一个新角色,发送一个 POST 请求到 roles 根路径:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"name": "Manager",
"ACL": {
"*": {
"read": true
}
}
}' \
https://{{host}}/1.1/roles
和创建对象类似,创建成功时,HTTP 返回 201 Created,Location header 包含了新的对象的 URL:
Status: 201 Created
Location: https://{{host}}/1.1/roles/55a483f0e4b05001a774b837
返回值是一个 JSON 对象:
{
"createdAt": "2015-07-14T03:34:41.074Z",
"objectId": "55a48351e4b05001a774a89f"
}
你可以通过加入已有的对象到 roles 和 users 关系中来创建一个有子角色和用户的角色:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"name": "CLevel",
"ACL": {
"*": {
"read": true
}
},
"roles": {
"__op": "AddRelation",
"objects": [
{
"__type": "Pointer",
"className": "_Role",
"objectId": "55a48351e4b05001a774a89f"
}
]
},
"users": {
"__op": "AddRelation",
"objects": [
{
"__type": "Pointer",
"className": "_User",
"objectId": "55a47496e4b05001a7732c5f"
}
]
}
}' \
https://{{host}}/1.1/roles
你也许注意到了,上面的代码里出现了一个新操作符 AddRelation。
因为一些性能上的考量,Relation 的实现比较复杂。
不过我们可以简单地把它看成 Pointer 数组。
一般推荐使用中间表而不是 Relation。
但由于一些历史原因,角色中还是用到了 Relation 这一概念。
获取角色
类似获取对象,你可以通过发送一个 GET 请求到 Location header 中返回的 URL 来获取这个对象,比如我们想要获取上面创建的对象:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/roles/55a483f0e4b05001a774b837
响应的 body 是一个 JSON 对象包含角色的所有字段:
{
"name": "CLevel",
"createdAt": "2015-07-14T03:37:20.992Z",
"updatedAt": "2015-07-14T03:37:20.994Z",
"objectId": "55a483f0e4b05001a774b837",
"users": {
"__type": "Relation",
"className": "_User"
},
"roles": {
"__type": "Relation",
"className": "_Role"
}
}
更新角色
更新一个角色通常可以像更新其他对象一样使用,但是 name 字段是不可以更改的。加入和删除 users 和 roles 可以通过使用 AddRelation 和 RemoveRelation 操作来进行。
举例来说,我们对 Manager 角色加入 1 个用户:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"users": {
"__op": "AddRelation",
"objects": [
{
"__type": "Pointer",
"className": "_User",
"objectId": "55a4800fe4b05001a7745c41"
}
]
}
}' \
https://{{host}}/1.1/roles/55a48351e4b05001a774a89f
相似的,我们可以删除一个 Manager 的子角色:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"roles": {
"__op": "RemoveRelation",
"objects": [
{
"__type": "Pointer",
"className": "_Role",
"objectId": "55a483f0e4b05001a774b837"
}
]
}
}' \
https://{{host}}/1.1/roles/55a48351e4b05001a774a89f
查询角色
查询用户具有哪些角色:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode 'where={"users": {"__type": "Pointer", "className": "_User", "objectId": "5e03100ed4b56c008e4a91dc"}}' \
https://{{host}}/1.1/roles
查询角色包含哪些用户(不计子角色中的用户):
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-G \
--data-urlencode '"$relatedTo":{"object":{"__type":"Pointer","className":"_Role","objectId":"5f3dea7b7a53400006b13886"},"key":"users"}' \
https://{{host}}/1.1/users
可以像查询普通对象一样,根据角色的属性进行查询。
删除角色
想要删除一个角色,只需要发送 DELETE 请求到它的 URL 就可以了。
我们需要传入 X-LC-Session 来通过一个有权限的用户账号来访问这个角色对象,例如:
curl -X DELETE \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "X-LC-Session: qmdj8pdidnmyzp0c7yqil91oc" \
https://{{host}}/1.1/roles/55a483f0e4b05001a774b837
角色和 ACL
当你通过 REST API 访问云服务的时候,访问和 SDK 一样可能被 ACL 所限制。你仍然可以通过 REST API 来读和修改 ACL,只用通过访问「ACL」键就可以了。
除了用户级的权限设置以外,你可以通过设置角色级的权限来限制对云端对象的访问。取代了指定一个 objectId 带一个权限的方式,你可以设定一个角色的权限为它的名字在前面加上 role: 前缀作为 key。你可以同时使用用户级的权限和角色级的权限来提供精细的用户访问控制。
比如,为了限制一个对象可以被在 Staff 里的任何人读到,而且可以被它的创建者和任何有 Manager 角色的人所修改,你应该向下面这样设置 ACL:
{
"55a4800fe4b05001a7745c41": {
"write": true
},
"role:Staff": {
"read": true
},
"role:Manager": {
"write": true
}
}
如果创建的用户和 Manager 本身就是 Staff 的子角色和用户,那么它们都会继承授予 Staff 的权限。 所以我们上面没有显式地为创建者和 Manager 授予「读」权限。
就像我们之前提到的一样,一个角色可以包含另一个,可以为 2 个角色建立一个「父子」关系��。 这个关系的结果就是任何被授予父角色的权限隐含地被授予子角色。
这样的关系类型通常在用户管理的内容类的 app 上比较常见,比如论坛。有一些少数的用户是「管理员」,有最高级的权限来调整程序的设置、创建新的论坛、设定全局的消息等等。
另一类用户是「版主」,他们有责任保证用户生成的内容是合适的。任何有管理员权限的人都应该有版主的权利。为了建立这个关系,你应该把「Administrators」的角色设置为「Moderators」的子角色,具体来说就是把 Administrators 这个角色加入 Moderators 对象的 roles 关系之中:
curl -X PUT \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"roles": {
"__op": "AddRelation",
"objects": [
{
"__type": "Pointer",
"className": "_Role",
"objectId": "<AdministratorsRoleObjectId>"
}
]
}
}' \
https://{{host}}/1.1/roles/<ModeratorsRoleObjectId>
文件
创建文件
REST API 不支持文件上传,请使用 SDK 或命令行工具上传并创建文件。
如果已有 URL,可以使用以下命令创建文件(在文件服务中新增一条数据):
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com/foo.jpg", "name": "foo.jpg", "mime_type": "image/jpeg"}' \
https://{{host}}/1.1/files
响应和返回值请参考前文创建对象一节。
关联文件到对象
一个文件被保存到文件服务后,你可以关联该文件到某个 LCObject 对象上:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
-H "Content-Type: application/json" \
-d '{
"name": "tom",
"picture": {
"id": "543cbaede4b07db196f50f3c",
"__type": "File"
}
}' \
https://{{host}}/1.1/classes/Staff
其中 id 就是文件对象的 objectId。
删除文件
知道文件对象 ObjectId 的情况下,可以通过 DELETE 删除文件:
curl -X DELETE \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/files/543cbaede4b07db196f50f3c
文件审核
你可以审核单个文件:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
https://{{host}}/1.1/files/:id/censor
其中 id 就是文件对象的 objectId。
数据 Schema
为了方便开发者使用、自行研发一些代码生成工具或者内部使用的管理平台。我们提供�了获取数据 Class Schema 的开放 API,基于安全考虑,强制要求使用 Master Key 才可以访问。
查询一个应用下面所有 Class 的 Schema:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
https://{{host}}/1.1/schemas
返回的 JSON 数据包含了每个 Class 对应的 Schema:
{
"_User": {
"username": { "type": "String" },
"password": { "type": "String" },
"objectId": { "type": "String" },
"emailVerified": { "type": "Boolean" },
"email": { "type": "String" },
"createdAt": { "type": "Date" },
"updatedAt": { "type": "Date" },
"authData": { "type": "Object" }
}
// 其他 class
}
也可以单独获取某个 Class 的 Schema:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
https://{{host}}/1.1/schemas/_User
数据导出 API
你可以通过请求 /exportData 来导出应用数据:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
-d '{}' \
https://{{host}}/1.1/exportData
exportData 要求使用 master key 来授权。
你还可以指定导出数据的起始时间(updatedAt):
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
-d '{"from_date":"2015-09-20", "to_date":"2015-09-25"}' \
https://{{host}}/1.1/exportData
还可以指定具体的 class 列表,使用逗号隔开:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
-d '{"classes":"_User,GameScore,Post"}' \
https://{{host}}/1.1/exportData
增加 only-schema 选项就可以只导出 schema:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
-d '{"only-schema":"true"}' \
https://{{host}}/1.1/exportData
导出的 Schema 文件同样可以使用数据导入功能来导入到其他应用。
默认导出的结果将发送到应用的创建者邮箱,你也可以指定接收邮箱:
curl -X POST \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
-H "Content-Type: application/json" \
-d '{"email":"username@exmaple.com"}' \
https://{{host}}/1.1/exportData
调用结果将返回本次任务的 id 和状态:
{
"status": "running",
"id": "1wugzx81LvS5R4RHsuaeMPKlJqFMFyLwYDNcx6LvCc6MEzQ2",
"app_id": "{{appid}}"
}
除了被动等待邮件之外,你还可以主动使用 id 去查询导出任务状态:
curl -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{masterkey}},master" \
https://{{host}}/1.1/exportData/1wugzx81LvS5R4RHsuaeMPKlJqFMFyLwYDNcx6LvCc6MEzQ2
如果导出完成,将返回导出结果的下载链接:
{
"status": "done",
"download_url": "https://download.leancloud.cn/export/example.tar.gz",
"id": "1wugzx81LvS5R4RHsuaeMPKlJqFMFyLwYDNcx6LvCc6MEzQ2",
"app_id": "{{appid}}"
}
如果任务还没有完成, status 仍然将为 running 状态,请间隔一段时间后再尝试查询。
导出应用数据中不包括即时通讯聊天记录。 如需导出这些记录,请调用相应的 REST API 接口获取。
其他 API
服务器时间
获取服务端当前日�期时间可以通过 /date API:
curl -i -X GET \
-H "X-LC-Id: {{appid}}" \
-H "X-LC-Key: {{appkey}}" \
https://{{host}}/1.1/date
返回 UTC 日期:
{
"iso": "2015-08-27T07:38:33.643Z",
"__type": "Date"
}
浏览器跨域和特殊方法解决方案
注:直接使用 RESTful API 遇到跨域问题,请遵守 HTML5 CORS 标准即可。以下方法非推荐方式,而是内部兼容方法。
对于跨域操作,我们定义了如下的 text/plain 数据格式来支持用 POST 的方法实现 GET、PUT、DELETE 的操作。
GET
curl -i -X POST \
-H "Content-Type: text/plain" \
-d \
'{"_method":"GET",
"_ApplicationId":"{{appid}}",
"_ApplicationKey":"{{appkey}}"}' \
https://{{host}}/1.1/classes/Post/<objectId>
对应的输出:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 04 Dec 2014 06:34:34 GMT
Content-Type: application/json;charset=utf-8
Content-Length: 174
Connection: keep-alive
Last-Modified: Thu, 04 Dec 2014 06:34:08.498 GMT
Cache-Control: no-cache,no-store
Pragma: no-cache
Strict-Transport-Security: max-age=31536000
{
"content": "每个 Java 程序员必备的 8 个开发工具",
"pubUser": "官方客服",
"pubTimestamp": 1435541999,
"createdAt": "2015-06-29T01:39:35.931Z",
"updatedAt": "2015-06-29T01:39:35.931Z",
"objectId": "558e20cbe4b060308e3eb36c"
}
PUT
curl -i -X POST \
-H "Content-Type: text/plain" \
-d \
'{"_method":"PUT",
"_ApplicationId":"{{appid}}",
"_ApplicationKey":"{{appkey}}",
"upvotes":99}' \
https://{{host}}/1.1/classes/Post/<objectId>
对应的输出:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 04 Dec 2014 06:40:38 GMT
Content-Type: application/json;charset=utf-8
Content-Length: 78
Connection: keep-alive
Cache-Control: no-cache,no-store
Pragma: no-cache
Strict-Transport-Security: max-age=31536000
{"updatedAt":"2015-07-13T06:40:38.310Z","objectId":"558e20cbe4b060308e3eb36c"}
DELETE
curl -i -X POST \
-H "Content-Type: text/plain" \
-d \
'{"_method": "DELETE",
"_ApplicationId":"{{appid}}",
"_ApplicationKey":"{{appkey}}"}' \
https://{{host}}/1.1/classes/Post/<objectId>
对应的输出是:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 04 Dec 2014 06:15:10 GMT
Content-Type: application/json;charset=utf-8
Content-Length: 2
Connection: keep-alive
Cache-Control: no-cache,no-store
Pragma: no-cache
Strict-Transport-Security: max-age=31536000
{}
总之,就是利用 POST 传递的参数,把 _method、_ApplicationId 以及 _ApplicationKey 传递给服务端,服务端会自动把这些请求翻译成指定的方法,这样可以使得 Unity3D 以及 JavaScript 等平台(或者语言)可以绕开浏览器跨域或者方法限制。