数据存储常见问题
API
API 调用次数有什么限制吗
使用 标准版,每天有 API 读写请求三万次的免费额度。
推送服务免费使用,并不占用免费额度,推送消息接口的调用受频率限制,具体参考:推送消息接口的限制 文档。
API 调用次数的计算
对于数据存储来说,每次 create 和 update 一个对象的数据算 1 次请求,如调用 1 次 object.saveInBackground 算 1 次 API 请求。在 API 调用失败的情况下,如果是由于应用流控超限(错误码 429)而被云端拒绝,则不会算成 1 次请求;如果是其他原因,例如权限不够(错误码 430),那么仍会算为 1 次请求。
一次请求
createsavefetchfinddeletedeleteAll
调用一次 fetch 或 find 通过 include 返回了 100 个关联对象�,算 1 次 API 请求。调用一次 find 或 deleteAll 来查找或删除 500 条记录,只算 1 次 API 请求。
多次请求
saveAllfetchAll
调用一次 saveAll 或 fetchAll 来保存或获取 array 里面 100 个 对象,算 100 次 API 请求。
对于 query 则是按照请求数来计费,与结果的大小无关。query.count 算 1 次 API 请求。collection fetch 也是按照请求次数来计费。
如何获取 API 的访问日志
开发者中心后台暂不支持查看 API 访问日志。
其他语言调用 REST API 如何对参数进行编码
REST API 文档使用 curl 作为示范,其中 --data-urlencode 表示要对参数进行 URL encode 编码。
如果是 GET 请求,直接将经过 URL encode 的参数通过 & 连接起来,放到 URL 的问号后。如 https://API_BASE_URL/1.1/login?username=xxxx&password=xxxxx。
查询
如何实现大小写不敏感的查询
目前不提供直接支持,可采用正则表达式查询的办法,具体参考 StackOverflow - MongoDB: Is it possible to make a case-insensitive query。
使用各平台 SDK 的 AVQuery 对象提供的 matchesRegex 方法(Android SDK 用 whereMatches 方法)。
查询最多能返回多少结果?
- 查询最多返回 1000 条数据。
- 返回的查询结果不止一个时,总大小不超过 6 MB(为了兼容旧客户端,超过 6 MB 时不会报错,会返回截断的结果);返回一个查询结果时,大小不超过 16 MB。
查询结果最多只能返回 1000 条数据,当我需要的数据量超过了 1000 该怎么办?
可以通过每次变更查询条件,来继续从上一次的断点获取新的结果,譬如:
- 第一次查询,createdAt 时间在 2015-12-01 00:00:00 之后的 1000 条数据(最后一条的 createdAt 值是 x);
- 第��二次查询,createdAt 在 x 之后的 1000 条数据(最后一条的 createdAt 是 y);
- 第三次查询,createdAt 在 y 之后的 1000 条数据(最后一条是 z);
以此类推。
可以通过指定 objectId 范围来实现分页吗?
当前数据存储服务自动生成 objectId 的算法是基于时间的,因此确实可以通过指定 objectId 范围来实现分页。
但是,从代码可读性及严谨性出发(比如导入数据时可以指定不同格式的 objectId),推荐通过指定 createdAt 范围来实现分页。
当数据量越来越大时,怎么加快查询速度?
与使用传统的数据库一样,查询优化主要靠索引实现。索引就像字典里的目录,能帮助你在海量的文字中更快速地查词。
原则:数据量少时,不建索引。多的时候请记住,建立索引后,写入时还需要更新索引,以此来换取更少的查询时间。所以,一般来说,写少读多就多建索引,写多读少就少建索引。
索引可以在 开发者中心 > 你的游戏 > 游戏服务 > 云服务 > 数据存储 中选择对应 Class 后进入「性能与索引」自助创建。
LeanCloud 查询支持 Sum、Group By、Distinct 这种函数吗?
不支持。Group By 查询往往涉及大量对象的遍历,数据存储并不适用这样的场景。
为此我们推荐使用「数据仓库」功能,它支持大量和高效的数据遍历,为数据分析这一场景量身定制。
默认值的查询结果为什么不对
这是默认值的限制。MongoDB 本身是不支持默认值,我们提供的默认值只是应用层面的增强,老数据如不存在相应的 key,设置默认值后并不会订正数据,只是在查询后做了展现层的优化。相应地,变更默认值后,这些 key 也会显示为新的默认值。有两种解决方案:
- 对老的数据做一次更新,查询出 key 不存在(whereDoesNotExist)的记录,再更新回去。
- 查询条件加上 or 查询,or key 不存在(whereDoesNotExist)。
如何查询非空值?
空值的具体语义取决于字段的类型和项目的实际情况。以字符串字段为例,空值可能意味着:
- 该字段不存在
- 该字段为
null - 该字段为空字符串
""
相应地,查询该字段非空的条件为 where={"some_field": {"$exists": true, "$nin": ["", null]}}。
在项目的数据模型设计阶段确定严谨的规范,有助于简化查询条件,避免因为不小心遗漏情况而出错。
例如,如果在设计上确保字符串字段为空时干脆不设置字段(不存在),永不将其设为 "" 和 null(强烈不推荐将字段设为 null,SDK 未提供将字段设为 null 的方法),那么只需查询 {"$exists": true} 即可。
地理位置查询错误
如果错误信息类似于 can't find any special indices: 2d (needs index), 2dsphere (needs index), for 字段名,就代表用于查询的字段没有建立 2D 索引,可以在 Class 管理的 其他 菜单里找到 索引 管理,点击进入,找到字段名称,选择并创建「2dsphere」索引类型。
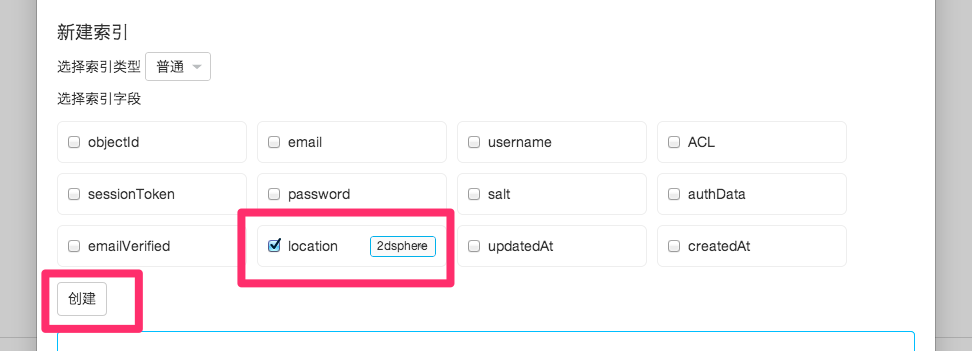
如何提升标志位的查询效率?
当数据表中有很多布尔类型的数据时,可以考虑使用二进制存储提高查询效率。例如需要存储是否开启推送、是否静音、是否为会员等多个状态,可以这样表示:
111:开启推送、静音、是会员
101:开启推送、未静音、是会员
在 LeanCloud 存储为整型字段,操作这个字段的方法可以参考位运算的接口文档:REST API - 位运算。
应用内搜索的关键字查询, 查出来的结果是两月前的数据,最新数据查询不到怎么办?
这种情况可以在 开发者中心 > 你的游戏 > 游戏服务 > 云服务 > 数据存储 > 全文搜索 尝试重建索引。
一般来说当用户上传了新的词典,或者有批量删除过数据等情况都需要执行一次「重建索引」操作。当发现搜索与存储数据不一致时,也可以尝试重建索引来解决。
某张表单个对象过大,导致请求速度较慢怎么办?
单个对象的数据过大,需要在业务层去优化代码,比如 data 是大数据字段:
- 在查询的时候,通过 AVQuery.Select 去选取需要的字段(不要 select data 字段)。
- 在 GET 对象的时候,才把 data 字段获取到客户端。
- 或者考虑将 data 字段的数据做为「文件」保存,然后在表中通过 Pointer 关联起来。
- 如果 data 是一个巨大的对象且只需要获取其中某个或某几个属性的话,可以考虑在 select 时用点号指定相��应的属性,参考 在查询对象时使用点号。
文件存储
文件存储有 CDN 加速吗?
中国节点的文件存储服务自带 CDN 加速访问,但不包括海外 CDN 加速。
可发工单申请开启海外 CDN 加速(开启后海外访问文件 http/https 流量费用分别上调为 0.40 元/GB、0.60 元/GB)。
国际版没有现成的 CDN 加速访问服务,需要用户自行配置。
以 CloudFront 加速服务为例,配置过程如下:
- 阅读官方指南 Getting Started with CloudFront。
- 创建一个 AWS 账户,开始使用 CloudFront 服务和付费。
- S3 的公共访问权限(read permission)已经被配置好,可以跳过指南中有关 S3 配置的部分。
- CloudFront 配置中的 Origin Domain Name 请从 AVFile 的 URL 中获取,其他均可保持默认。
文件存储有大小限制吗?
没有。
除了在浏览器里通过 JavaScript SDK 上传文件,或者通过我们网站直接上传文件,有 10 MB 的大小限制之外,其他 SDK 都没有限制。 JavaScript SDK 在 Node.js 环境中也没有大小限制。
存储图片可以做缩略图等处理吗?
可以。默认我们的 AVFile 类提供了缩略图获取方法,可以参见各个 SDK 的开发指南。如果要自己处理,可以通过获取 AVFile 的 URL 属性。
使用 七牛图片处理 API 执行处理,例如添加水印、裁剪等。
文件存储支持访问控制吗?
由于知道文件 URL 的任何用户都可以访问文件,因此需要为 _File Class 和引用文件的 Class 设置合适的 Class 权限和 ACL,限制未授权用户获取到文件 URL。
如果希望能够更精细地控制文件访问权限,比如在一定时间后重新检查是否有权访问文件,建议使用支持访问权限控制的第三方文件存储服务商,然后直接在 LeanCloud 文件服务中保存一个外部的 URL。
注意 _File 表是不可变的,这意味着已经写入的 URL 不能修改。
但通常支持访问权限控制的文件存储服务商,实现访问权限的方式都是在现有的 URL,比如 https://file.example.com/some-url 后额外传入一个 token 参数(这个 token 通常有时效性),比如 https://file.example.com/some-url?token=xxxxxx。
所以客户端需要访问文件时,可以先从 LCFile 获取 url 属性后,再加上这个 token 参数,拼成最终的 URL 下载文件。
token 的获取需要自行在云引擎或自己的服务器上部署一个简单的生成访问 token 的 API 服务,客户端访问该 API 服务获取 token。
如何修改文件存储中已有的文件?
文件存储对应的 _File Class 是不可变数据,文件内容和相关元数据一经写入就无法修改,只能删除后重新上传或重新通过 URL 构建。
在使用外部文件(通过 URL 构建文件)的情况下,如果有频繁修改文件或相关元数据的需求,可以考虑如下方案:
- 自己实现一个存储外部文件相关信息的 Class,比如
ExternalFile。在引用该文件的对象中设置 Pointer 字段,指向ExternalFile。注意,这种情况下,查询包含文件的对象时,如果希望同时获取文件信息,需要 include 相应字段(使用内置_FileClass 的情况下会自动 include,不用另外指定)。 - 在需要引用文件的对象中,直接使用字符串类型保存 URL。这种情况下文件相关功能都需要自行实现。如果想要保存这个文件的相关元信息,还需要另外设计。比如在对象的其他字段上保存,或者将相应字段的类型从字符串改成 object,同时保存 URL ��和元信息。注意,如此设计会导致应用的文件信息分散在需要用到文件的各个 Class 中,要对整个应用的文件进行批量查询和批量处理会比较麻烦。
SDK
iOS 项目打包后的大小
创建一个全新的空白项目,使用 CocoaPod 安装了 AVOSCloud 和 AVOSCloudIM 模块,此时项目大小超过了 80 MB。打包之后体积会不会缩小?大概会有多大呢?
数据存储 iOS SDK 二进制中包含了 i386、armv7、arm64 等 5 个 CPU slices。发布过程中,non-ARM 的符号和没有参与连接的符号会被 strip 掉。因此,最终应用体积不会增加超过 10 MB,请放心使用。
Java SDK 对 AVObject 对象使用 getDate("createdAt") 方法读取创建时间为什么会返回 null
请用 AVObject 的 getCreatedAt 方法;获取 updatedAt 用 getUpdatedAt。
这两个方法会返回 Date 类型。
如果希望返回字符串类型,可以使用 getUpdatedAtString() 和 getCreatedAtString()。
Android 设备每次启动时,installationId 为什么总会改变?如何才能不改变?
可能有以下两种原因导致这种情况:
- SDK 版本过旧,installationId 的生成逻辑在版本更迭中有修改。请更新至最新版本。
- 代码混淆引起的,注意在 proguard 文件中添加 SDK 的混淆排除。
Android 代码混淆怎么做
参考 Android 代码混淆 文档。
Java SDK 出现 already has one request sending 错误是什么原因
日志中出现了 com.avos.avoscloud.AVException: already has one request sending 的错误信息,这说明存在对同一个 AVObject 实例对象同时进行了 2 次异步的 save 操作。为防止数据错乱,数据存储 SDK 对于这种同一数据的并发写入做了限制,所以抛出了这个异常。
需要检查代码,通过打印 log 和断点的方式来定位究竟是由哪一行 save 所引发的。
使用 Android SDK 的数据存储功能,APP 上架时被厂商检测存在自启动问题。
解决办法:将 Android SDK 升级到 v8.2.19 及以上版本。
自启动问题是因为 LiveQuery 需要在后台有一个长链接,这样才能及时收到云端的事件通知,而这个长链接是放在一个后台 Service 里面的,并且有自动重连的能力——这会监听网络状态变化,在网络有效的时候启动这个 service。这个逻辑可能会被一些平台判定为「自启动」。
老版本 SDK 因为没有适配 Android 新版本,所以有时候会抛出异常。8.2.19 版本 SDK 对 Android 新系统进行了适配,但是也并没有完全禁止这个自动重连的逻辑,所以可能还是会被误判。如果已经使用新版 SDK 但仍遇到这个问题,可以向厂商申诉。
JavaScript SDK 有没有同步 API
JavaScript SDK 由于平台的特殊性(运行在单线程运行的浏览器或者 Node.js 环境中),不提供同步 API,所有需要网络交互的 API 都需要以 callback 的形式调用。我们提供了 Promise 模式 来减少 callback 嵌套过多的问题。
JavaScript SDK 在 AV.init 中用了 Master Key,但发出去的 AJAX 请求返回 206
目前 JavaScript SDK 在浏览器(而不是 Node)中工作时,是不会发送 Master Key 的,因为我们不鼓励在浏览器中使用 Master Key,Master Key 代表着对数据的最高权限,只应当在后端程序中使用。
如果你的应用的确是内部应用(做好了相关的安全措施,外部访问不到),可以在 AV.init之后增加下面的代码来让 JavaScript SDK 发送 Master Key:
AV.Cloud.useMasterKey(true);
JavaScript SDK 会暴露 App Key 和 App Id,怎么保证安全性?
首先请阅读 安全总览 来了解数据存储服务完整的安全体系。
理论上所有客户端都是不可信任的,所以需要在服务端对安全性进行设计。如果需要高级安全,可以使用 ACL 方式来管理,如果需要更高级的自定义方式,可以使用 云引擎。
其他
如何防止 DDoS 攻击,或者高频次的 CC 攻击?
详见 TDS 云服务带高防吗。
保存数据时报错 The key is too long,是什么问题?
可以检查要保存或更新的字段是否设置了索引,有索引的字段长度限制不能超过 1 KB。
如何解决数据一致性或事务需求?
数据存储服务目前并不提供完整的事务功能,但提供了一些保证数据一致性的特性,可以解决大部分的一致性需求:
- 在单个对象的一次 save 操作中,对多个字段的更新操作是原子地完成的。
- 使用 increment(原子计数器)可以原子地更新数字字段。
- 唯一索引 可以保证在一个字段上有同样值的对象只有一个。
- 有条件更新对象 可以仅在满足某个查询条件时进行更新操作;在这个特性的基础上,你可以自己实现更加复杂的 两阶段提交。
- 在云引擎上还可以借助 LeanCache 来实现自定义的 排他锁。
关于这个话题我们还录制了一期公开课视频,其中有对上面这些特性的详细介绍,和解决常见场景的实例教程(包括实现两阶段提交)。